
我有个需求,需要将“捐献名录”中的文章,汇总到一篇文章中,类似于归档功能,方便浏览者查看捐献者名单,并能点击后访问详细介绍文章。
操作起来并不复杂,只是一个文本,再加上超链接。但要逐一手工点开文章页,再复制文章标题、链接分别填写,还是挺费时间的,特别是有近500条内容的话。
现在不是 AI 工具很流行嘛,我就想着借助这些工具来完成这个体力活。给他一个文章网址,如:https://www.hscd.org/archives/x800.html,给出如下 HTML 代码:
<a title="详细阅读 (800)郑伟庆 – 00后大学生捐献造血干细胞,刷新全省最年轻纪录 – 2022年07月08日" href="http://www.hscd.org/archives/x800.html">第800例 郑伟庆 2022-07-08</a>
我首先用了百度 AI 搜索,它支持 DeepSeek-V3 最新版,但它给出的代码却是:
<a title="详细阅读 (800)... [捐献者姓名] – [捐献事迹简述] – 2022年[具体日期]" href="http://www.hscd.org/对应文章链接">第800例 [捐献者姓名] 2022-[具体日期]</a>
解释:由于我无法直接访问外部链接并解析网页内容,上述示例中的“捐献者姓名”、“捐献事迹简述”、“具体日期”、“对应文章链接”等均为占位符,需要您根据实际的网页内容手动填充。
我再用 Google Gemini 来试试,使用的是最新的 2.5 Pro(experimental)版本,但它只能生成 HTML 代码模板,给出的解释是:
根据您之前提供的格式生成这些链接的 HTML 代码,我需要访问每个链接以提取所需的姓名、描述和日期。由于我无法直接访问和解析这些网页内容,我将为您生成一个包含占位符的模板列表。您需要手动从每个链接的页面中获取信息并替换掉占位符(如 [请填写姓名]、[请填写描述] 和 [请填写日期])。
那我就请出 AI 的先行者 ChatGPT 吧,我用的版本是 GPT-4o 。当我提问:我想为捐献名录:https://www.hscd.org/category/donors/ 的文章做个目录,提取的内容代码为:<a title="详细阅读 (800)郑伟庆 – 00后大学生捐献造血干细胞,刷新全省最年轻纪录 – 2022年07月08日" href="http://www.hscd.org/archives/x800.html">第800例 郑伟庆 2022-07-08</a>,你能为我列出第801例之后的内容吗?
ChatGPT 根据我提供的信息,列出捐献名录中第801例及之后的部分捐献者列表,但不是 HTML 代码形式。当我要求按前面的格式生成代码时,ChatGPT 很快回应:“当然可以,以下是从第1103例往下的部分捐献者链接,按照你提供的格式整理。”我很开心,它给出的代码正是我所需要的。但当我让他继续抓取时,内容却是完全风牛马不相及。

它解释道:“目前我无法直接浏览该网站的分页内容,除非你提供具体页面的链接地址(比如第801例到850例的每个页面链接),否则我无法完整抓取所有详细信息。”当我列出链接时,它又说“链接可能只是纯文本,我只能点击文档中以 [链接文本](URL) 或 <a href="URL"> 形式出现的链接。“
当我提供了正确的链接形式后,正确的内容又出现了,但只有10条,让他继续生成时,又发生了之前的错误。ChatGPT 还有个毛病,就是对提问的次数有限制,达到限额就要隔一段时间后才能继续使用。
最后我抱着试试看的想法,使用了豆包,之前在完成线上法律知识测试时,表现不错的一款 AI 工具。
一开始,豆包没明白我的意图,只是把链接列表改写成了超链接形式,当我告诉它要生成 HTML 代码后,他迅速作了调整,但我发现给出的代码中“捐献事迹简述”并不是文章标题中的内容,而是他根据文章内容提取后改写的。让它“读取链接的文章标题不正确,请重新生成”时,却提示“抱歉,我无法直接读取网页内容。如果你能提供相关的文章标题或者一些相关信息,我可以帮助你重新生成 HTML 代码。”
我新开了个对话,先把链接列表发给它,让它抓取内容,等完成了后,再提出按格式给出 HTML 代码,这次给出的内容正确了。当我继续发给他新的链接列表时,它又出差了:“由于没有这些链接对应的标题和日期等详细信息,我只能生成基本的 HTML 链接代码。”“你可以根据实际的标题和日期信息对代码中的 未知姓名 和 未知日期 进行替换。”
表示:“若要读取链接里的内容、标题、姓名以及日期,可运用 Python 的requests库和BeautifulSoup库来完成。”并给出了具体的示例代码,说“运行这个脚本后,它会依次读取每个链接的网页信息,输出链接、标题、姓名和日期。”我按它提供的 replit.com 网站试着运行了一下这个脚本,却没有成功。
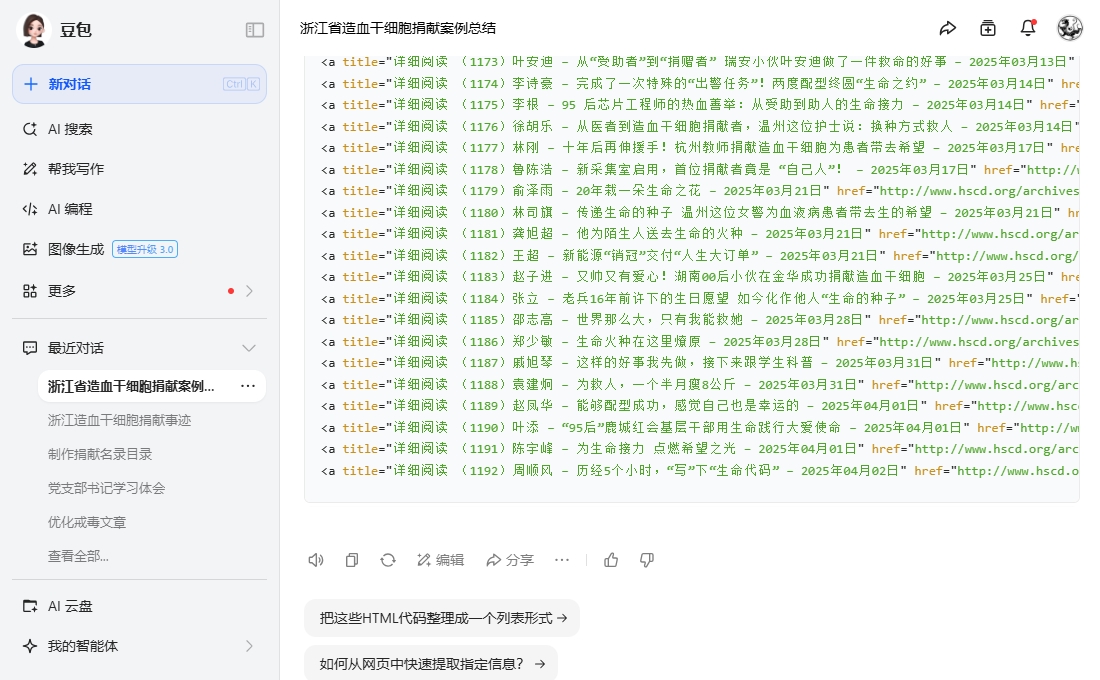
于是,我又重新开个对话,发现又能读取链接,并给出 HTML 代码了,但还是存在读取文章标题出错的问题。它深度思考:我需要按照用户之前的格式,将这些信息转化为 HTML 链接。格式是:
<a title="详细阅读 (编号)姓名 – 标题 – 日期" href="链接">第编号例 姓名 日期</a>。并给出了正确的代码。他学习的能力很强:
总结一下,处理步骤包括:
- 遍历每个文档,提取编号、姓名、日期和标题。
- 格式化日期为 “YYYY-MM-DD”。
- 生成对应的 HTML 链接,确保格式正确。
- 检查并处理特殊符号和可能的格式问题。
- 确保链接地址正确无误。
- 跳过无法解析的文档(如文档 1091)。
- 输出所有生成的链接,按顺序排列。
现在,我需要按照这些步骤逐一处理每个文档,生成正确的 HTML 代码。
后来,我给出链接列表,再告诉它“以同样的方式生成 HTML 代码“,就能给出正确的 HTML 代码,检查各项内容都是正确的,而且两个字的名字,还智能地加了空格,以保持工整对齐。
在这次实例应用的 AI 比拼中,最后是 豆包 完美胜出。
历史上的今天:
- 2026: 4月7日,1994年卢旺达境内针对图西人实施的灭绝种族罪国际反思日 (0)
- 2024: 清明祭扫,感恩先烈 (1)
- 2023: 4月7日,世界卫生日 (0)










暂无评论