
毋容置疑,机器学习正在改变我们今天正处的时代。
机器学习所带来的生产力是极具颠覆性的。不再只是动作僵硬,步伐一致的“机器产品”,而是已经演化为创新的生产形态。我们不仅可以让模型自主从庞大的文本和图像数据中实现能力的升级迭代,还可以在不同场景中实现高效率生产力的部署。
无论你是正在使用或者计划使用,你都需要明确,机器学习在未来很长一段时间内,会成为影响每个人和企业发展的重要因素。尤其是相关原生应用已成为大势所趋,或许真就用不了两年,我们所见皆被颠覆。
为什么选择“Amazon SageMaker”
“21世纪什么最贵?人才!”
这句出自2004年电影《天下无贼》中的一句经典台词,放到今天,依旧适用。发展机器学习的本质是要从根本改变生产方式。它们之所以能够无缝地应用到企业场景中,除去大规模数据的训练,还有编制完备、技术娴熟的团队支持。
通常,企业想要应用机器学习,需要由数据科学家负责研究和制定机器学习模型,开发人员再将模型转换为可用的产品或 Web 服务 API。其中,会面临诸如数据清洗、模型调优、模型部署等多方面的难题。
但近20年的科技发展带来的变化是,我们已经可以用“技术创造技术”。这也是机器学习之所以能够大步发展的关键。Amazon SageMaker,帮助想要发展机器学习的企业实现“拎包入住”,带着自己的算法、代码以及数据,“肆意开荒”,入门机器学习的门槛被降低。它提供了一个完全集成的开发环境,提供了数据探索和可视化工具,支持快速迭代、高精度训练,并且可通过一键式部署工具实现轻松的模型部署。
那么,如何使用 Amazon SageMaker 训练出具备思维能力、有逻辑、能推理、会生产的高性能机器学习模型? 现在,跟着这份保姆级教程,开启你的机器学习之路吧。
当然,在开始之前,请先确保自己拥有亚马逊云科技账户。如果您还未注册账户,请依照文章尾部的详细流程进行注册。
一、自动创建机器学习模型
我们可以通过 Amazon SageMaker Autopilot 自动创建、训练、调优机器学习(ML)模型。
开发者只需提供数据,并交代任务(预测的目标是哪一列),其余工作均由Autopilot完成,如数据清洗、特征选取、算法挑选与超参调优等。
第1步:设置 Amazon SageMaker Studio 域
- 登录 CloudFormation 控制台,设置 SageMaker Studio 账户名称和描述,并勾选同意创建 IAM 资源选项,点击创建堆栈。堆栈状态提示为“COMPLETE”时,即为完成。

- 在CloudFormation 控制台搜索栏中输入 SageMaker Studio,进入设置页面,选择 Studio 以使用 studio-user 配置文件打开 SageMaker Studio。
第2步:任务设置
- 打开控制台,点击“+”图标,新建Amazon SageMaker Autopilot 任务。
- 进行任务设置,包括实验名称、原始数据在S3的存放路径、目标变量的位置,输出模型存放的位置,并选择机器学习任务。这里可以选择二分类、线性回归和多分类。当然,你也可以通过选择“Auto”,让 Amazon SageMaker Autopilot根据目标数据属性自动选择机器学习任务。
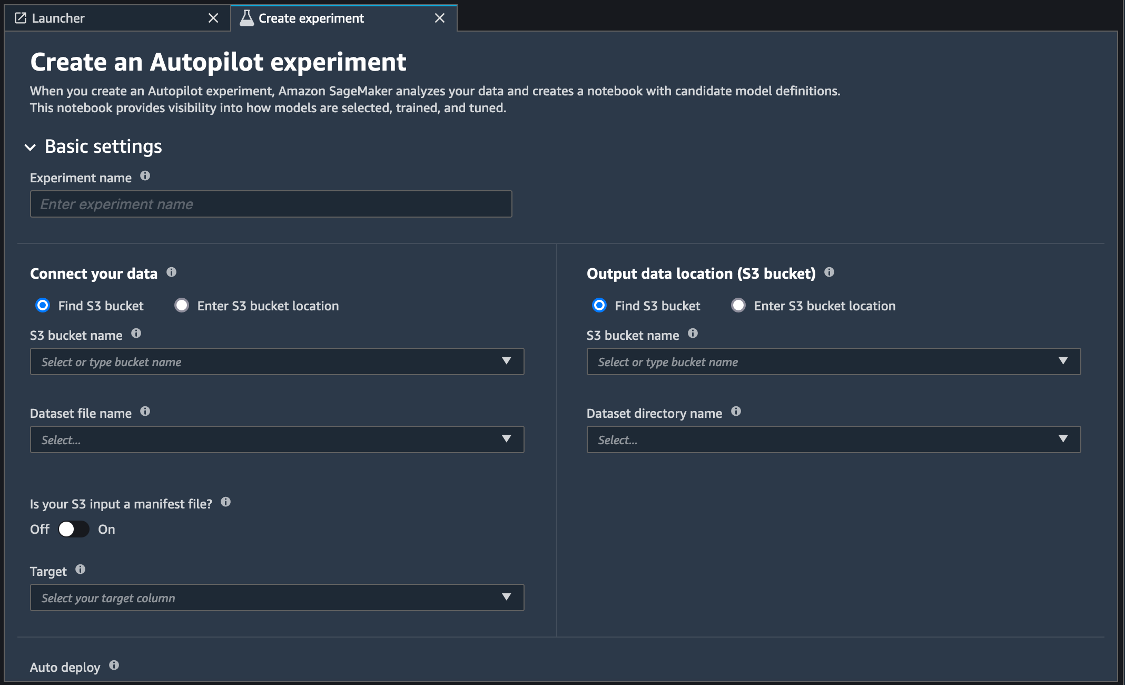
- 点击创建任务。SageMaker Autopilot 将开始运行实验的各个阶段。在实验窗口中,您可以追踪预处理、候选定义、特征工程、模型调优、可解释性和洞察阶段的进度。
第3步:解读模型性能
- 实验完成后,我们可以在模型详细信息中查看模型的性能统计数据。分别点击可解释性、性能、生成物以及网络选项卡,查看模型不同类型的详细数据。
注意:实验结束后,请删除您不再使用的资源,以免产生意外费用。
二、构建、训练和部署机器学习模型
第1步:创建 Notebook 实例
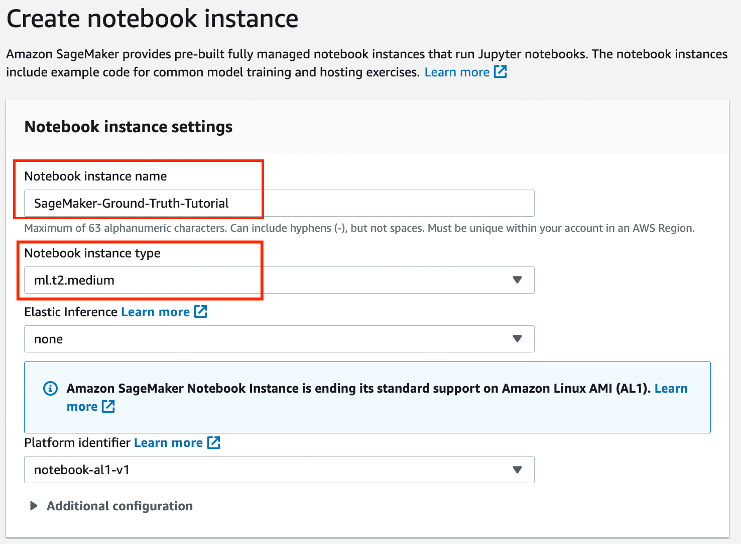
- 登录亚马逊云科技控制台,选择“Amazon SageMaker”,在左侧导航栏中的“笔记本”选项中选择“笔记本实例”,点击创建笔记本实例。这里需要设置笔记本实例名称、选择笔记本实例(t2.micro 为亚马逊云科技提供的免费实例)以及卷的大小。卷的大小默认是 5 GB,如有额外数据需求,可手动进行调整。
此外,如需要进行权限和加密、网络、Git存储库、标签的设置,点击下拉框即可。通常情况下,我们需要对权限和加密进行设置。
注意:在创建Amazon SageMaker笔记本实例之前,通常不需要申请特定的服务配额。SageMaker的使用通常受亚马逊云科技账户的默认限制和配额,对于常规用途是足够的。如需创建大量的SageMaker笔记本实例或者需要更高的资源限制,需要申请增加服务配额。可在 Service-Quota 配额控制台请求增加配额。
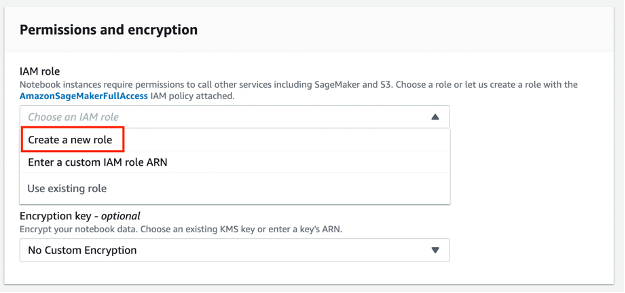
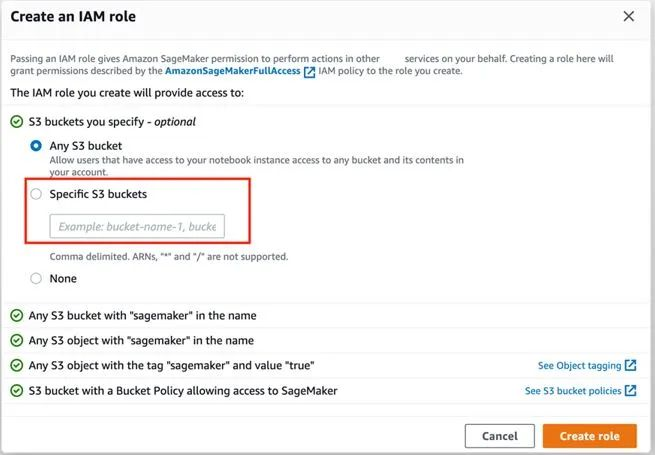
- 在进行权限和加密进行设置前,需要创建一个 IAM 角色,用来访问其他亚马逊云科技服务和资源。选择“任意 S3 存储桶”,点击“创建角色”即可。如果之前创建过 Notebook 实例,可选择之前创建好的角色。
- 最后,点击“创建笔记本实例”,等待新创建的笔记本实例的状态由“Pending”变为“InService”时(通常需要5分钟),笔记本电脑实例即创建完成。点击Open Jupyter,在 Jupyter Notebook 界面中可选择创建开发环境。
第2步:创建 Jupyter 笔记本
点击打开 Jupyter,在右上角的 New 中新建一个“conda_python3”的脚本,并设置笔记本名称。该预装环境包括默认的 Anaconda 安装和 Python 3。
第3步:处理数据集
- 使用SHAP(SHapley Additive exPlanations)库将数据集加载到笔记本实例中,查看数据集,对其进行转换,然后将其上传到 S3 中。您也可通过运行脚本代码,查看数据集的统计概览和可视化图。
注意:如果当前的 Jupyter 内核没有 SHAP 库,请运行 %conda install -c conda-forge shap 进行安装。
- 使用Sklearn 将数据集拆分成训练集和测试集。训练集用于训练模型,而测试集用于评估最终训练模型的性能。使用固定的随机种子对数据集进行随机排序:训练集占数据集的 80%,测试集占数据集的 20%。
- 拆分训练集,分离出验证集。验证集用于评估训练模型的性能,同时调整模型的超参数。训练集的75% 将成为最终的训练集,其余的则是验证集。检查数据集的分割和结构是否符合预期。
- 将训练和验证数据框对象转换为CSV 文件,用于匹配 XGBoost 算法的输入文件格式。使用 SageMaker 和 Boto3,将训练和验证数据集上传到默认的 S3 存储桶。
第4步:训练模型
- 为数据集选择正确的算法。可以使用 SageMaker XGBoost 的内置算法,无需对模型进行预先评估。
- 导入Amazon SageMaker Python SDK,首先从当前 SageMaker 会话中获取基本信息;使用estimator.Estimator 类创建 XGBoost 预估器,它简化了在SageMaker上进行机器学习工作的流程,包括数据准备、训练、部署和推理。
- 调用预估器的set_hyperparameters 方法设置 XGBoost 算法的超参数;使用 TrainingInput 类配置用于训练的数据输入流。开始模型训练,使用训练和验证数据集调用预估器的拟合方法。通过设置 wait=True,拟合方法会显示进度日志并等待训练完成。
- 模型创建完成,SageMaker 会将模型工件存储在您的 S3 存储桶中。
第5步:部署模型
调用 xgb_model 预估器的部署方法,部署训练好的模型。调用部署方法时,必须指定用于托管端点的 EC2 ML 实例的数量和类型。
立即开启机器学习之旅
传统的机器学习开发是一个复杂、昂贵、迭代的过程,而且没有任何集成工具可用于整个机器学习工作流程,这让它难上加难。使用 Amazon SageMaker ,消除机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松,享受更少的工作量和更低的成本,为生产力和竞争力增添「UP BUFF」。
现在注册亚马逊云科技账号,立即体验 Amazon SageMaker 提供的高效创新力和生产力。
完整注册流程如下:
一、邮箱验证
前往账号亚马逊云科技注册页面
https://aws.amazon.com/cn/free/?sc_channel=seo&sc_campaign=blog0908
1.填写您注册账号的邮箱, 点击“继续”。
2.查收验证邮件。
3.输入邮箱中收到的验证码 , 点击“继续”。

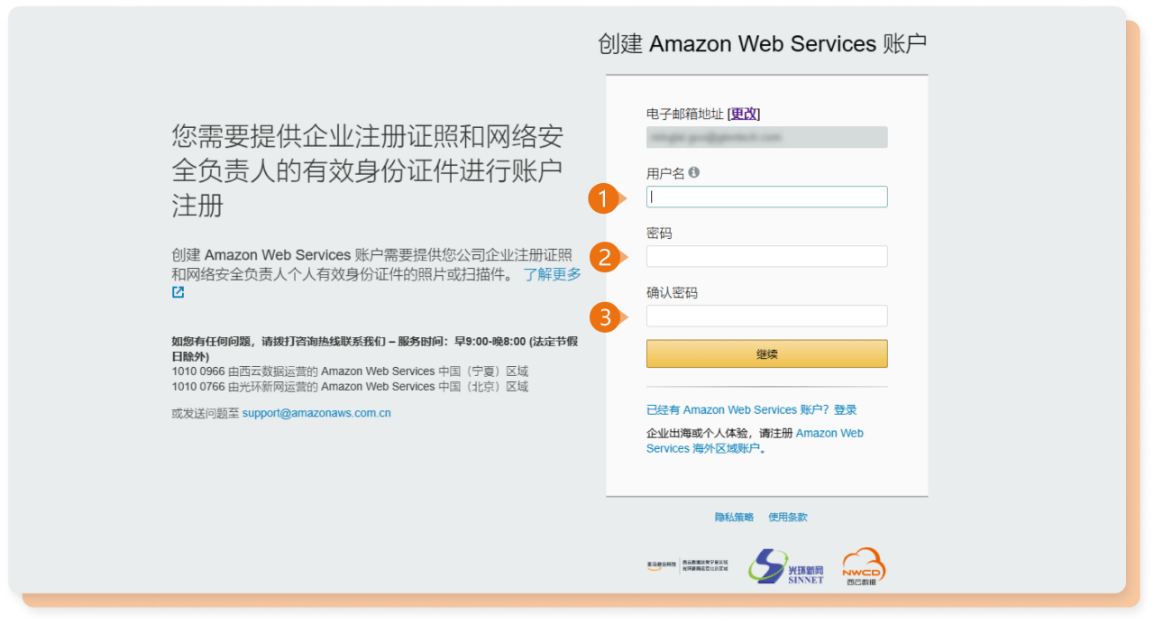
二、设置用户名密码
1.输入您的账号用户名。
2.输入您的账号密码。
3.再次输入,确认您的账号密码。
三、填写账号联系人以及公司信息
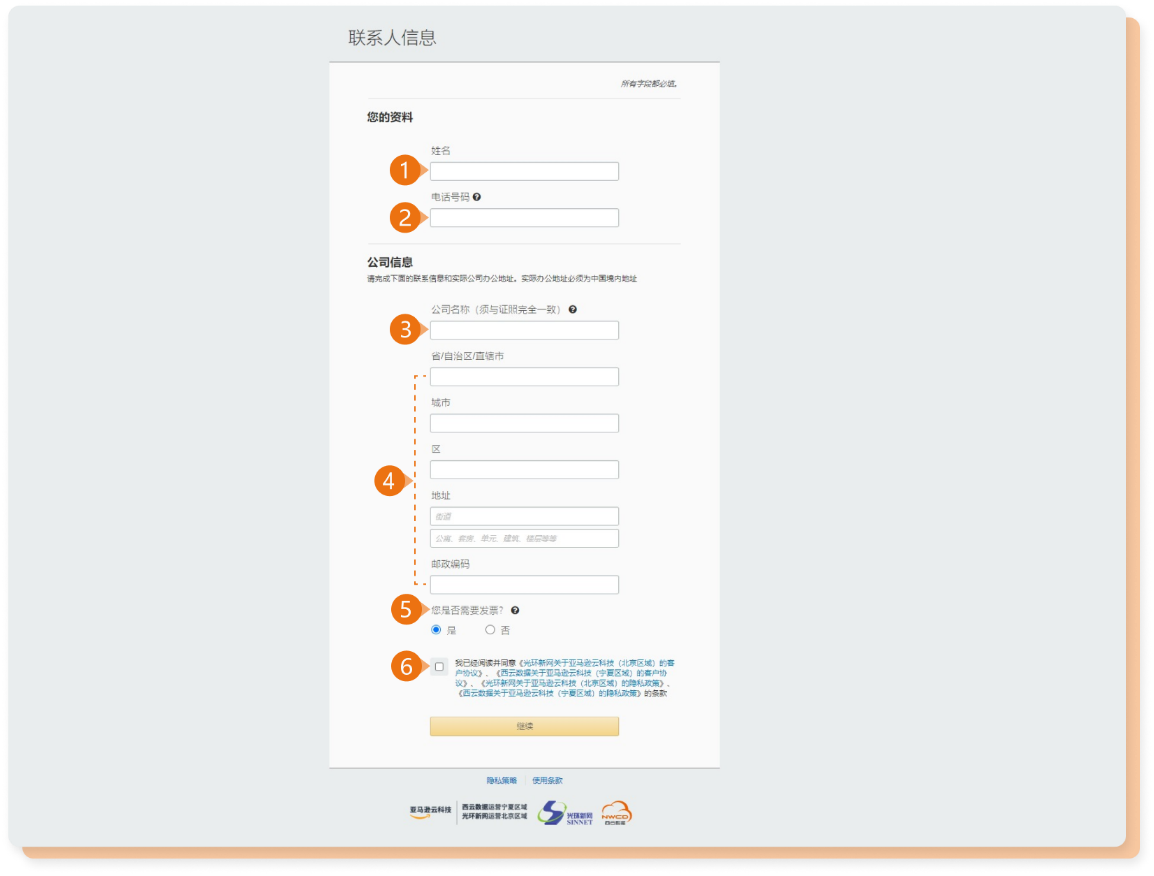
- 1.填写公司联系人姓名全称。
- 填写公司联系人联系电话。
- 3.填写公司名称,请务必与您所提供的营业执照公司名称保持一致。
- 4.填写公司办公地址。
- 5.选择是否需要发票。
- 6.查看客户协议,并完成勾选。
四、企业信息验证
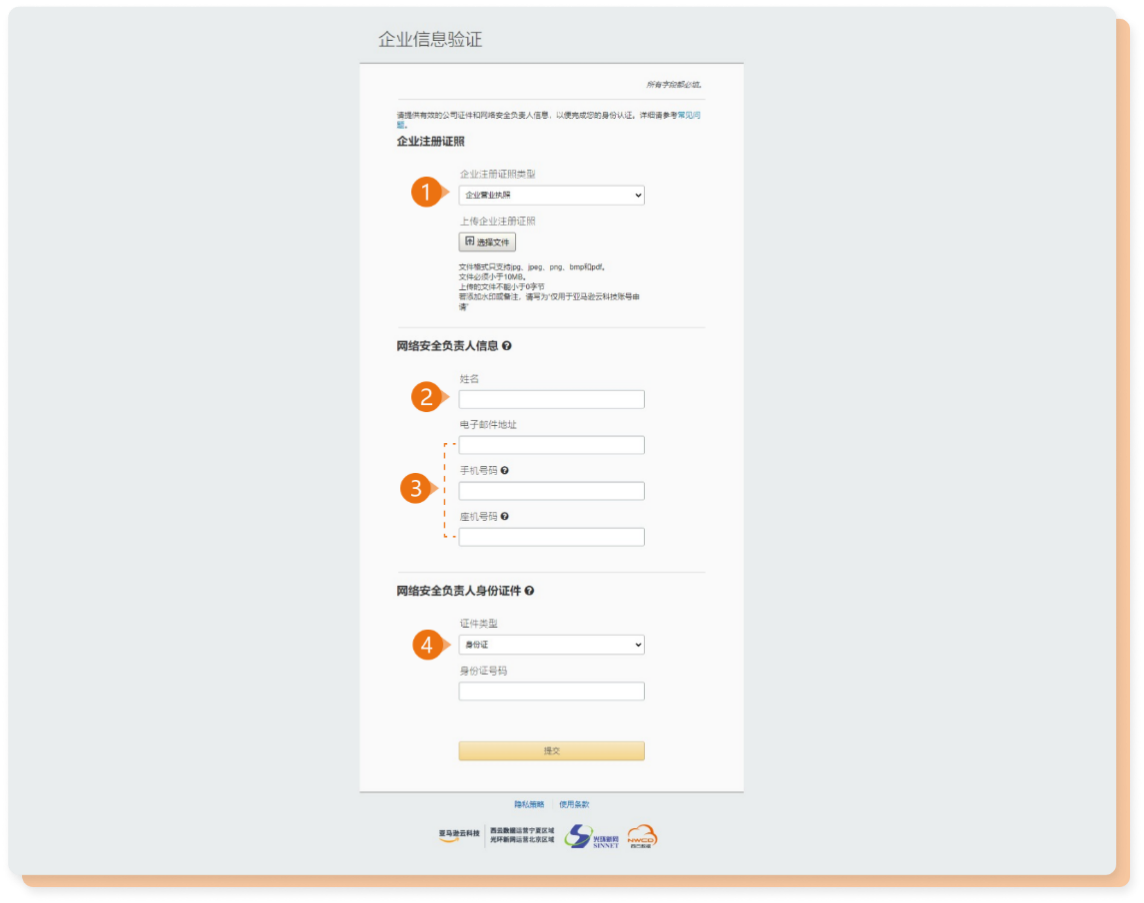
1.上传企业营业执照。
2.填写网络安全负责人姓名。
3.填写网络安全负责人联系方式。
4.上传网络安全负责人身份证件。
五、完成手机验证
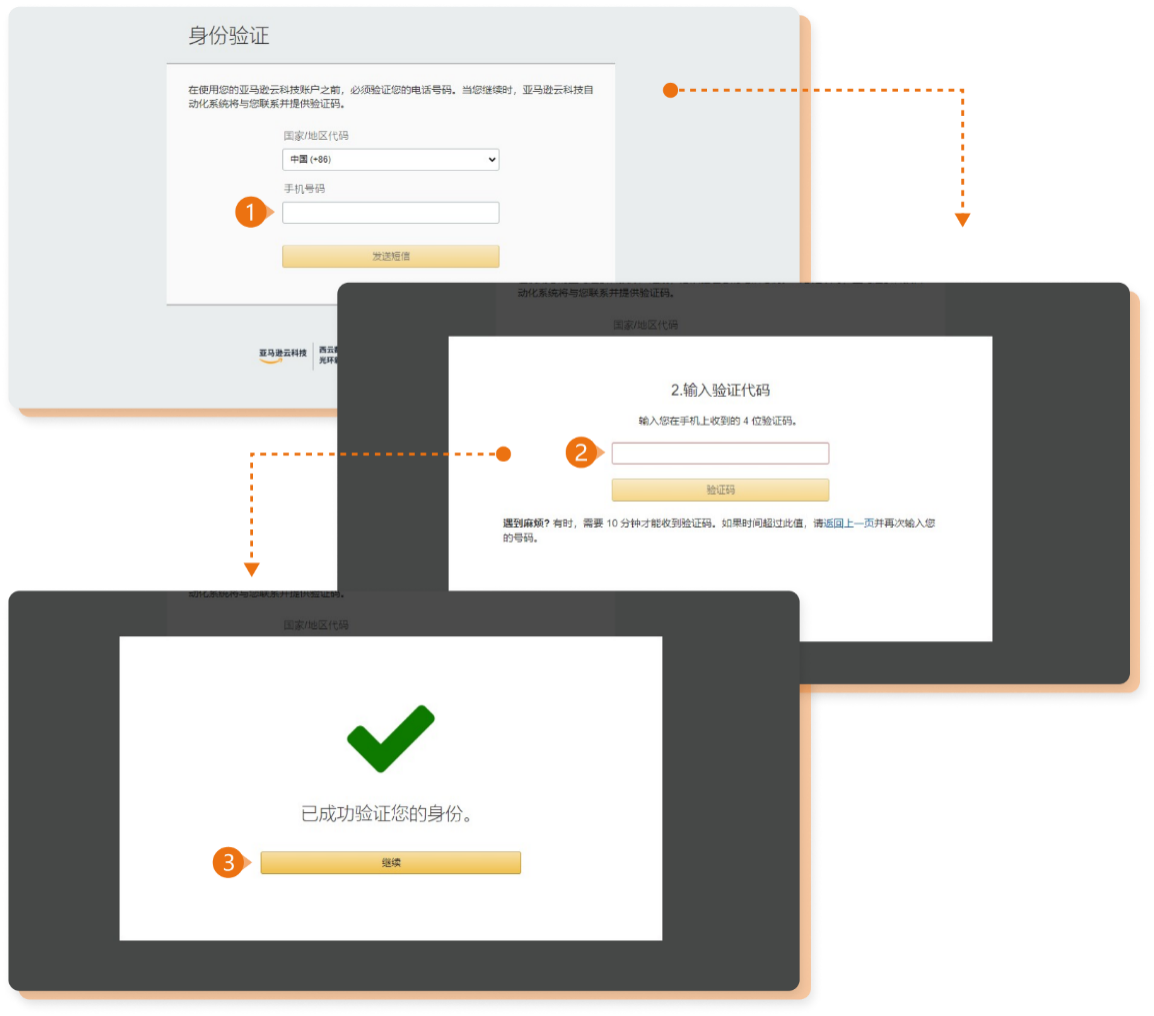
1.填写手机号。
2.输入验证码。
3.完成验证,点击继续。
六、选择支持计划
根据企业具体需求,选择符合的支持计划。
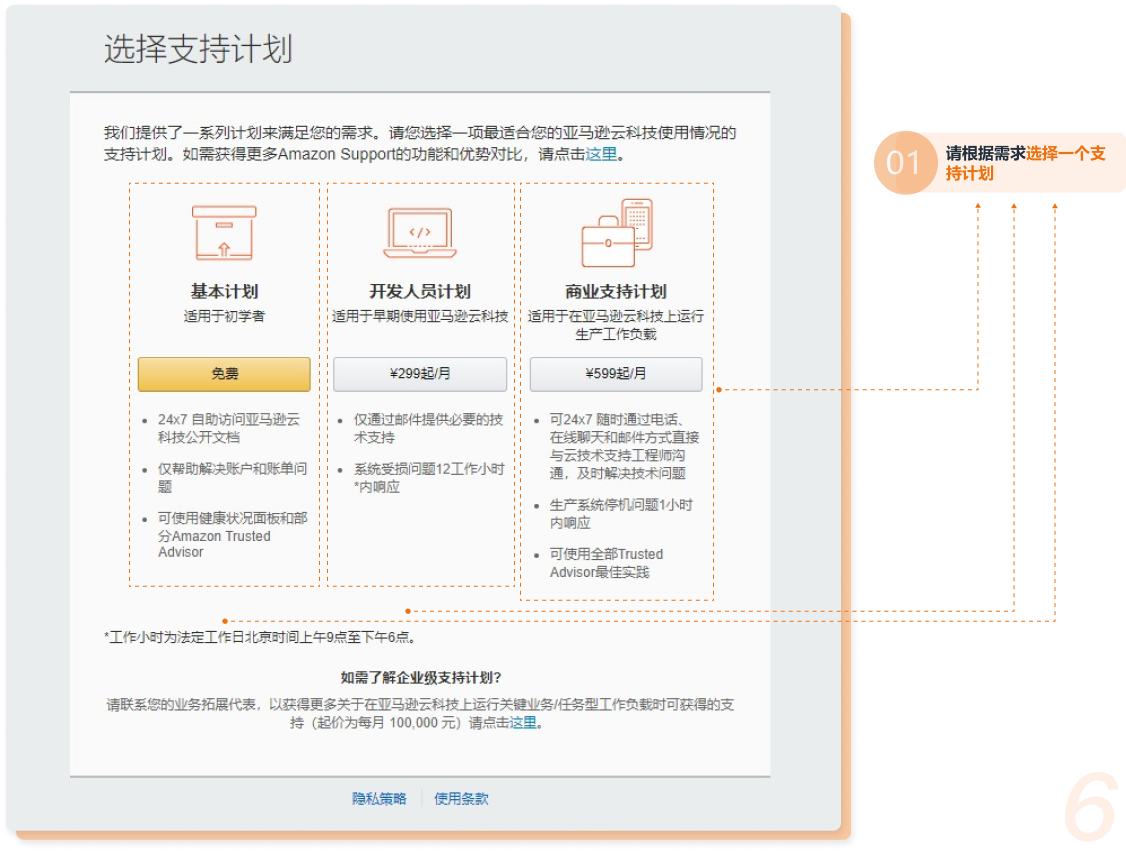
七、等待注册结果。
历史上的今天:
- 2022: 9月27日,世界旅游日 (0)








暂无评论